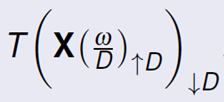Multi-modal, deep learning, audio, video, text, deep networks, AR, VR, traffic, surveillance, smart cameras.
IRIS Webinar
In the area of multimodal learning, our goal is to learn subtle but implicit relations that tie video + audio + text together in streaming multimedia content. The general idea is to fill-in for deficits in one modality by harnessing information coming from other modalities. In addition, such a learning also has the potential to advance the state of the art in many of the current problems that researchers are looking at including video captioning, video retrieval, audio enhancement using video, video interpolation, and so on.
Computer vision is maturing by the day and smartphone camera manufacturers are waiting to cash in on these advances in a big way. A possible dimension that is being touted is that of vision-enabled AR in mobile cameras. The impact can be huge as mobiles pervade each and every home. Our efforts will be directed at enabling new 3D experiences from cellphone cameras by duly processing images from multiple lenses by enforcing scene and view consistencies. We will come up with algorithms that are faithful to the underlying physics of image formation to deliver not only novel 3D experiences but to also augment it by introducing special effects such as rain, haze, and lighting.
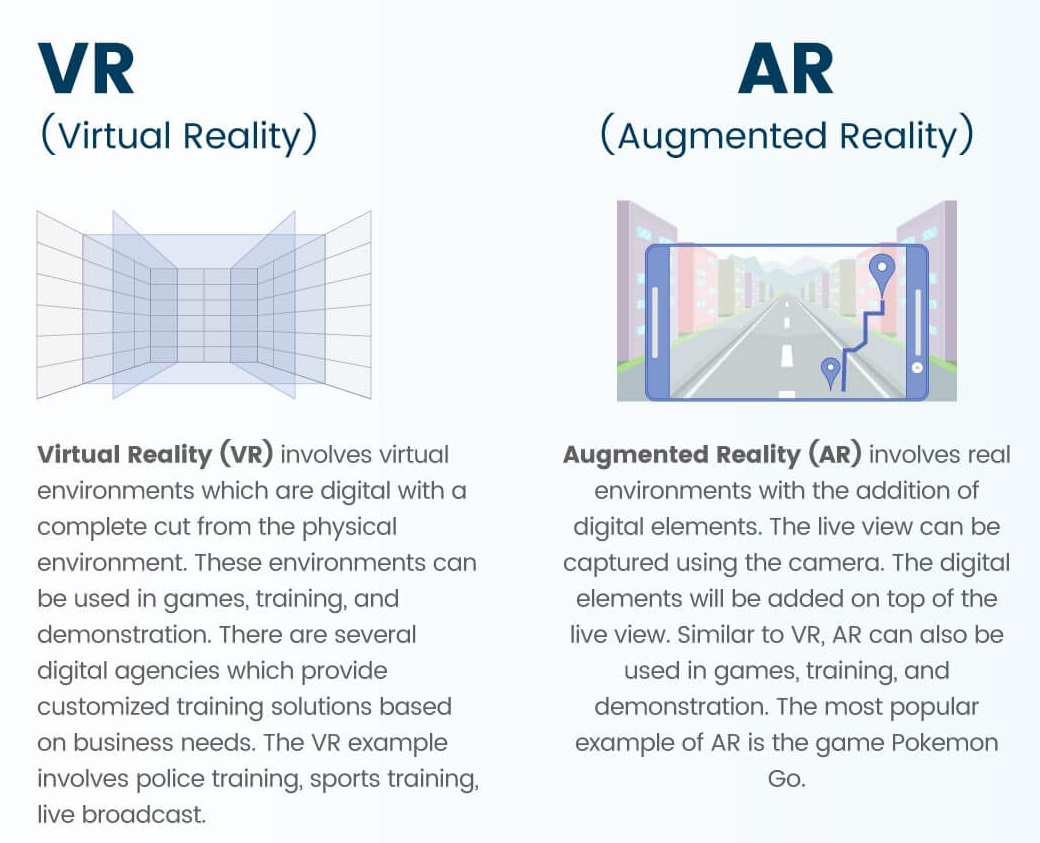
VR vs AR
These days it is a common sight to spot cameras that dot every conceivable signal junction on roads. Our goal is to crunch the information streamed by a plethora of such cameras to produce high-level inferences. This problem is challenging due to the varying nature of vehicles, unexpected traffic conditions, positioning of cameras and their viewpoints, pose variations, lighting and so on. We believe that with the a judicious combination of datasets, annotations, network architecture, and camera correspondences, it should be possible to unearth a wealth of information that can make traveling on roads safe and smart.
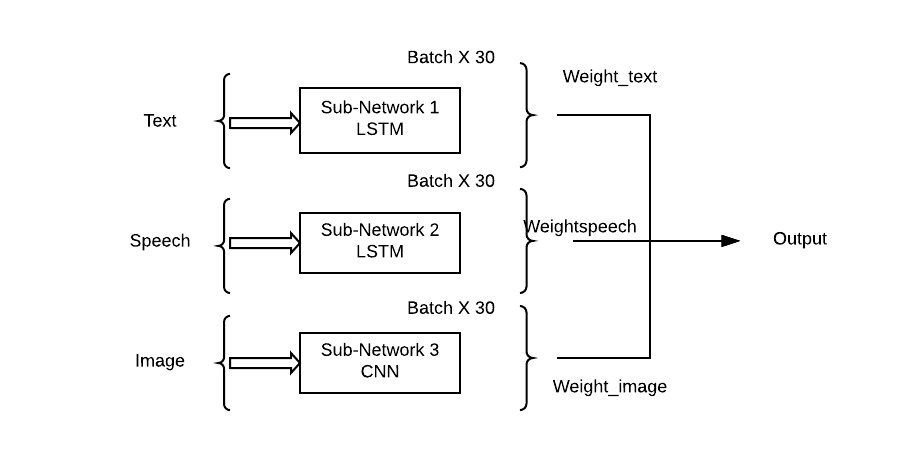
Multi-modal Deep Learning
Social media abounds with data that involve video, audio and text, sometimes individually (as in pure videos),sometimes in pairs (as in captioned videos, or video with audio, or audio with caption) and sometimes all together (such as in narratives). While our main target is to address all three together, the framework that we will propose can handle them all individually, or in pairs, or all together as a whole depending upon the availability of data. Given the correlated nature of the three modalities present in a video, several novel tasks can be proposed. The idea here is to unlock and unleash the subtle relations that exist among video, audio and text. Interestingly, these three modalities are not perfectly aligned at any given point of time but they are bunched along the time axis may be with some small lag or lead.
It is this subtle and implicit relation that we are interested in unravelling. It may be noted that this relation is difficult to model with traditional methods and deep networks are the way to go. Some of the problems where we see direct implications of this capability are in image classification, video retrieval, video captioning, image super-resolution, and image interpolation. In the literature, these problems have been addressed independently by different researchers. We will harness our multimodal learning capability to handle them all under a common umbrella. One can attempt to solve these problems in a supervised manner or with unsupervised data.
While unsupervised approach sounds very appealing it may not always be possible to adopt it. In supervised training, data is already available in annotated form. The ground truth labels (for a classification problem) or the expected output (if it is a regression problem) are known a priori and the network is trained to produce the desired output for a given input.
VR/AR for mobile cameras
We also wish to investigate the problem of enabling AR in mobile cameras. Present-day smartphones typically employ unconstrained cameras for complimentary functionalities. This produces images that have been afflicted by asymmetric distortions (e.g., via resolutions, defocus/motion blurs, etc.). Therefore, it is important to study how images captured by such unconstrained lens- configurations can be fused to get a reliable stereo depth map and hence a stereo pair. It then remains to split the mobile display to stream the left and right views and view through a simple splitter to perceive the 3D world.
Such a mechanism would have a telling experience when watching live sports. A user can switch between the normal mode (which is monocular) to the AR mode (which would stream stereo pairs to enable 3D viewing). Thus, a simple smartphone can double up to provide an enriching experience of the 3D world as we would like to perceive it.
The above is just one facet of the problem. Imagine that I am watching a scene with my camera but suddenly wish for an augmented experience; say how would the scene look like if it was a rainy day? This is what we term as augmented or mixed reality. While part of the video is real (i.e the scene that is being observed by the user) the rainy part is unreal. Now here is the challenge. Many works exist for tackling the problem of deraining i.e clean up a rainy picture. These methods typically use rainy images that are synthesized from clean images using physical models that can explain the phenomenon of rain. However, our requirement is different. We wish for the user to experience a 3D world on a rainy day.
Thus, we have to produce stereo pairs that are not only scene consistent (in terms of color, lighting etc) but are also view-consistent (faithful to 3D geometry). For example, rendering rain independently in stereo images may create inconsistent rain-pattern in left-right views, leading to confusion in the observer’s mind. As mentioned before, even creating such a database would be an excellent contribution by itself to the vision community as currently there are no such datasets.
Traffic Inference
In any metro, one typically finds at least 4 cameras in most signal junctions and these have been laid all over the city. The idea is to be able to build deep networks that can crunch these large volumes of data and arrive at meaningful decisions. More specifically, the network should be able to flag traffic jams, slow moving traffic, accidents, crowd gathering, unruly mobs, signal violation, processions, to name a few. One can think of this network as a classifier and each of the above could be treated as a class label. The input to the network would be the live video stream from signal junctions.
An expected bottleneck with such an exercise is availability of data. In this regard, our initial focus would be to search for data sets online on traffic videos and supplement them with videos on Youtube depicting different situations as envisaged above. Our network should have the capability to discount small changes such as viewpoint changes, road conditions, height of installation, camera make and so on and only extract features at different layers of depth that are most relevant for solving the task at hand. Also, we need to be able to train the network for night conditions since that is when many accidents happen. Night vision can be expected to be more challenging than during daylight. Another related problem is that of vehicle classification as they cross signal junctions.
A count of the number of vehicles of different types can be a valuable input for traffic rerouting and even road restructuring to enable smooth flow of traffic. An entirely different dimension to this problem emerges when we consider weather conditions. How do we build deep networks that can perform the above tasks in a weather-agnostic manner? Even how to train these networks is not fully understood. One possibility is to use recovery tools that can handle rain, haze, snow and clean up the frames to the extent possible and then use the already trained network for getting the output.
However, this seldom works because existing deraining and dehazing approaches tend to produce artifacts that confuse a network that has been trained on clean data. Another option would to directly train a network in an end-to- end fashion by showing input images degraded by rain or haze and seek classification results at the output. This will require ground truth annotation on such degraded images.
Expected deliverables of the research
Publications and visible output
Manpower development
International collaborations, education programs and conferences
Industrial collaborations
Current status
We have developed a deep network-based dynamic scene deblurring method for unconstrained dual lens cameras that elegantly addresses the view-inconsistency issue using a coherent fusion module.
We are building a multi-modal deep network that takes monocular audio as input and produces a stereo output by harnessing visual frame information for guidance under a weakly-supervised setting
We are in the process of buying high-end GPU systems and hardware for AR and VR.
PAPER-1
Dynamic Scene Deblurring for Unconstrained Dual-lens Cameras
Why Dual-lens Cameras
A DL camera captures depth information, which supports many applications.
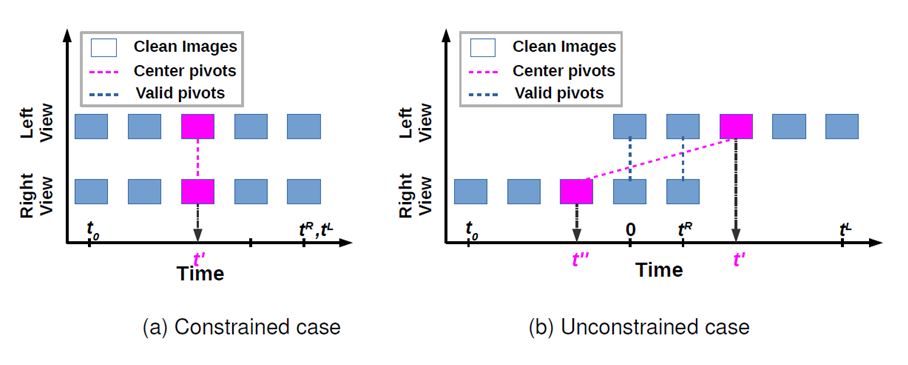
Constrained Vs Unconstrained DL Cameras
Constrained DL cameras use multiple cameras of identical configuration.
Present-day DL Cameras are mostly unconstrained by employing different configuration.
Motion Blur Problem in Unconstrained DL
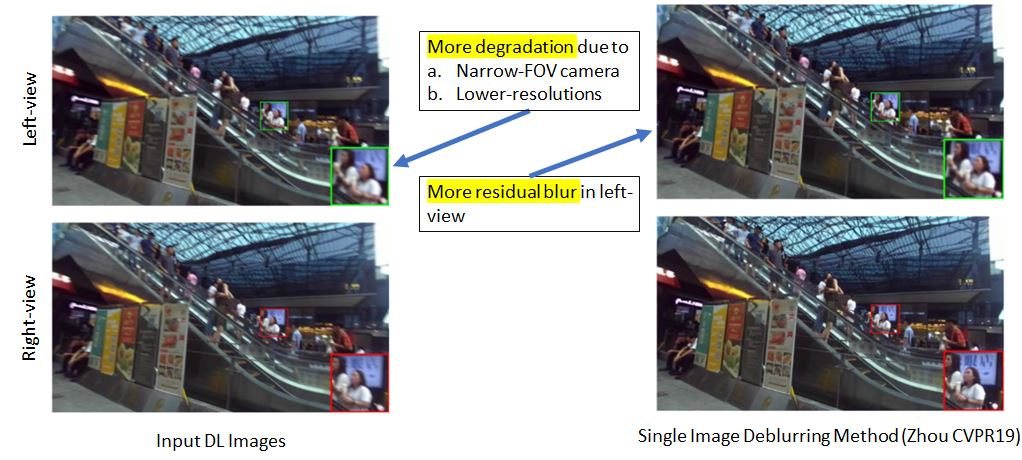
Due to unconstrained nature of two cameras, blur in both views can be different.
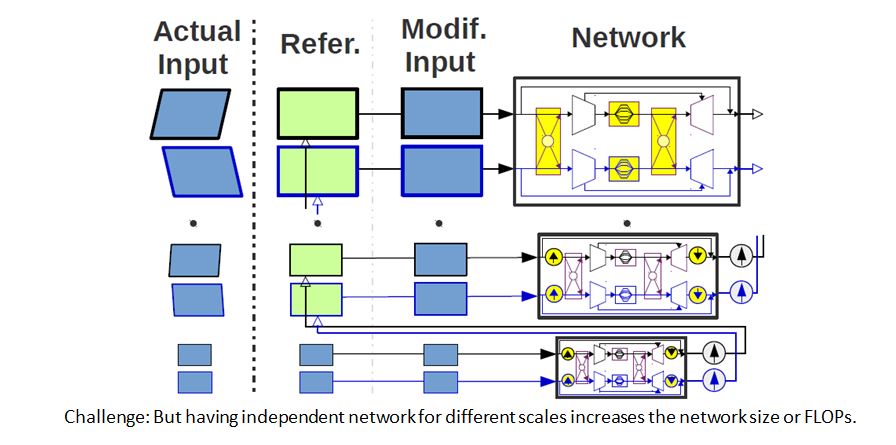
Challenges in Unconstrained DL Deblurring
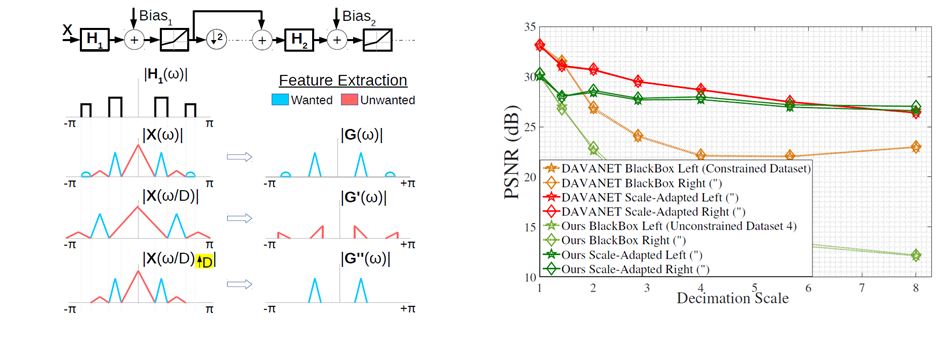
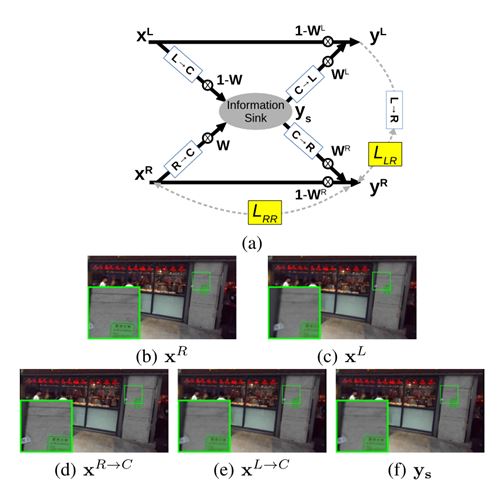
Due to different exposure, depth information in deblurred image-pair can be inconsistent. Soln: An Adaptive Scale-Space Approach
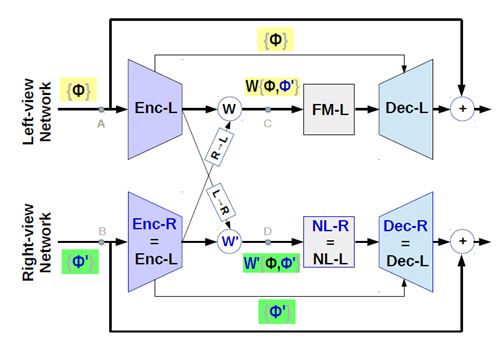
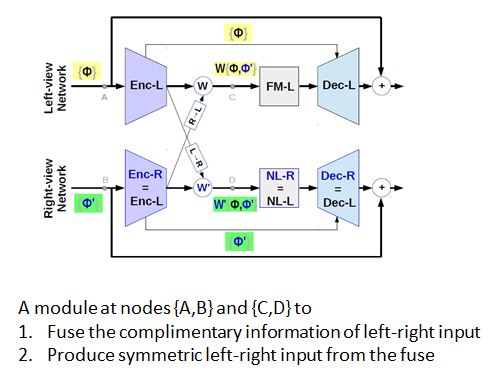
Deblurring quality of left-right views can be different. Soln: A Coherent Fusion Module
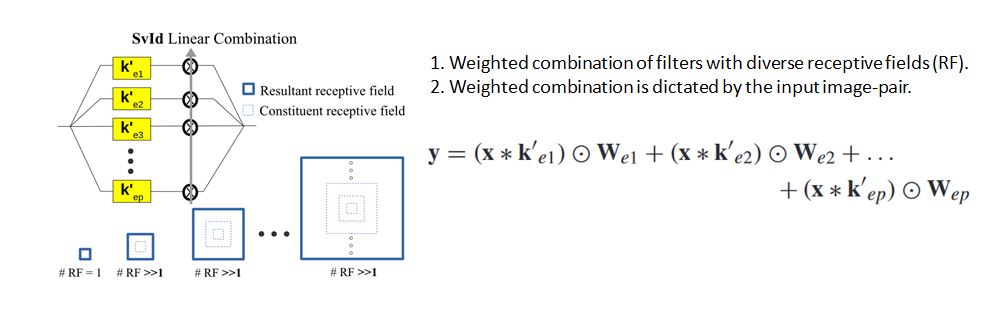
Blur at different regions can be different due to Dynamic Scenes. Soln: Space-variant Image-dependent Module
Depth-Inconsistency: Source of the problem
To capture consistent-depth in dynamic scene, time instances of left-view and right-view must be identical.
Blur becomes lesser at lower scales, and so is the time inconsistency due to blur.
Can we use the same network for different scales? No
Remark 1: If a transformation T() is applicable for a given signal in frequency domain X(Ѡ), then for a similar mapping for
the down sampled signal X(Ѡ/D), one has to modify the transform as
View-inconsistency: Source of the problem
Problem: Blur is different in left-right view due to unconstrained DL set-up
Main Reason: Symmetric Left-right networks get dissimilar input features
Main Reason: Symmetric Left-right networks get dissimilar input features
Space-Variant Blur: Source of the Problem
In dynamic scenes, different parts of images can have different blur characteristics.
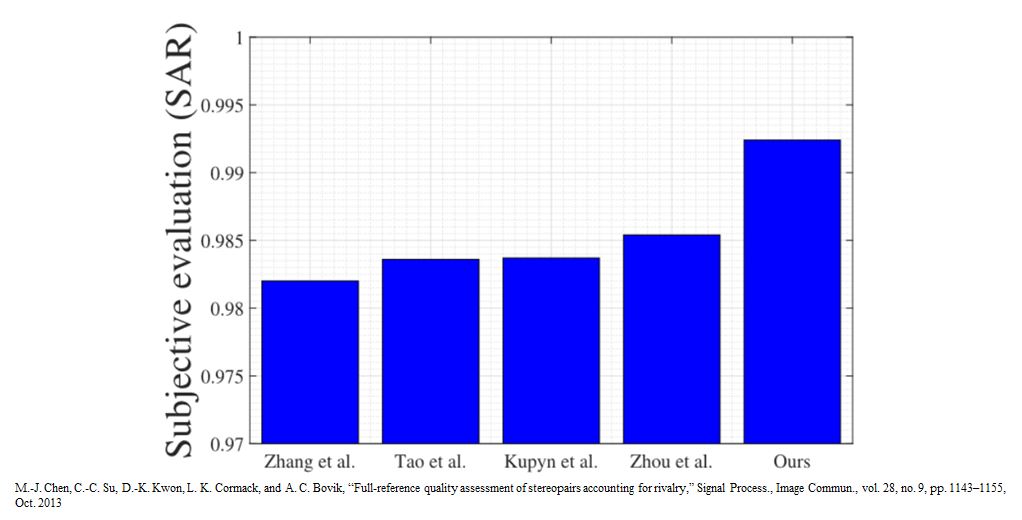
Results:
View-consistency in Deblurring
Real Experiments
Conclusion
As a first, present a deep learning method to address the problem of dynamic scene deblurring in unconstrained DL cameras.
Introduced three modalities:
Adaptive scale-space method for scene-consistent depth.
Coherent fusion for view-consistency.
Space-variant module for adaptive filter with diverse receptive fields.
PAPER-2
Audio Spatialization
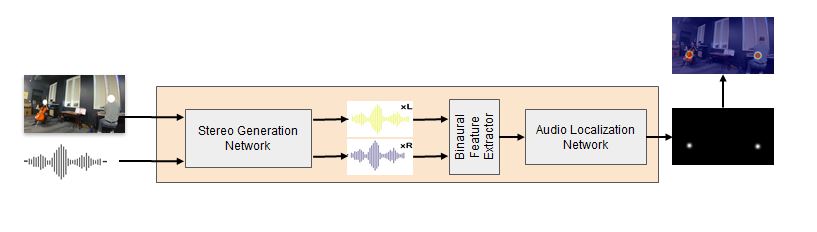
The goal is to generate binaural audio from monaural audio using cues from visual stream for any given video.
Previous Works
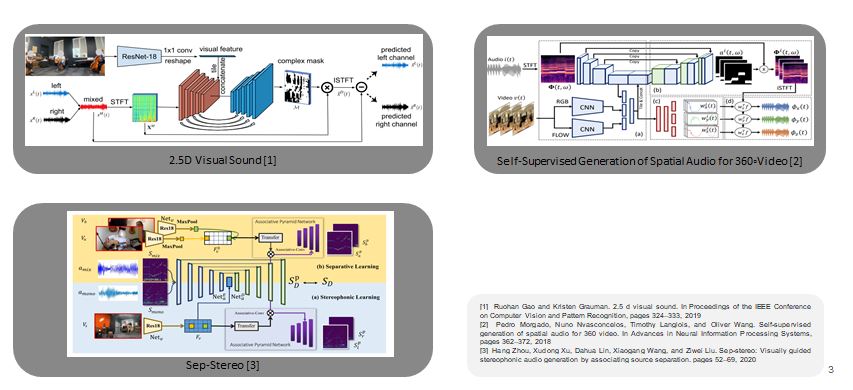
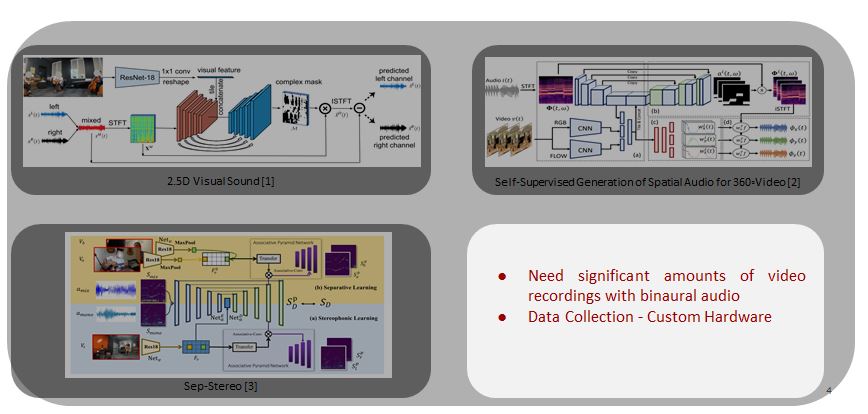
Previous works attempted to solve this problems in a fully-supervised learning setup using videos with accompanying binaural audios.
However, these approaches require significant amounts of binaural video recordings.
And creating such datasets requires custom hardware which are expensive.
Key Idea
We try to address the problem of binaural audio generation with minimal supervision.
Design a downstream task which can only be solved by binaural-audio.
Object localization from audio is feasible only if the audio contains binaural cues.
We subsequently attempt to leverage this localization capability to solve the inverse problem of generating binaural from monaural audio with minimal supervision.
To address these issues, we look into the problem of generating binaural audio with minimal supervision.
Our key idea is that any downstream task that can be solved only using binaural audios can be used to provide proxy-supervision for binaural audio generation.
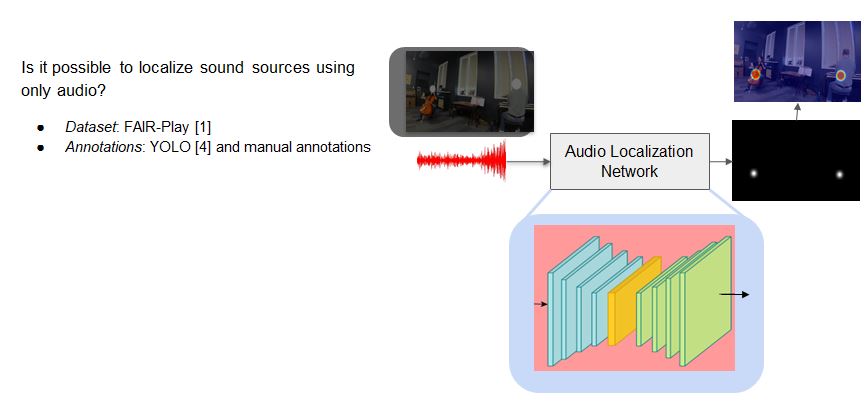
Visual Sound Source Localization using Audio
Input to the audio-localization network is only audio.
And it outputs a visual saliency map indicating the location of the sound sources on the visual frame.
We use auto-encoder architecture for this.
On the other hand, any audio representation with some binaural cues, either binaural audio or explicit binaural cues such as ILD & IPD, is able to localize sound sources well.
Note that the network only looks at audio, not visual frame.
On the other hand, binaural audio is able to localize sound sources well.
If we extract the binaural cues ILD & ITD and use them as input.
This was done keeping in mind that research attributes the ability of humans to localize sound sources to binaural cues such as the IPD and ILD.
Localize to Binauralize
Goal: Generate Binaural audios with minimal explicit binaural-supervision
How? Proxy-supervision: Create a downstream task that can be constrained such that only binaural audio can solve it.
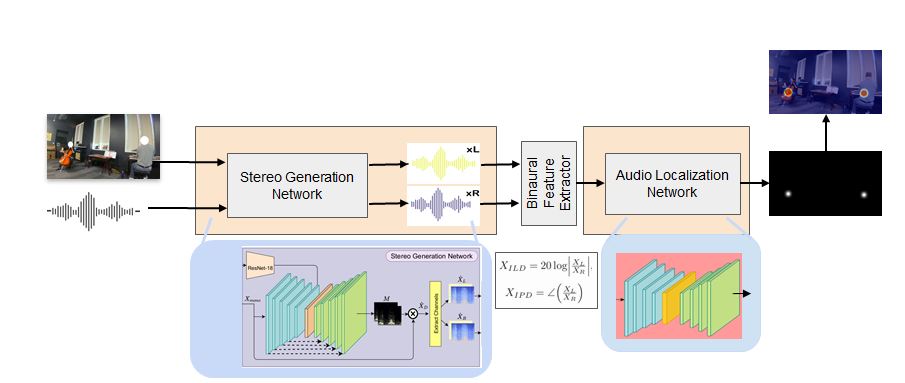
Localize-to-Binauralize Network (L2BNet):
Stereo-Generation (SG) network
Audio-Localization (AL) network
Which are them fed as input to the Audio-Localization network.
Is Visual Sound Source Localization sufficient for generating binaural audio?
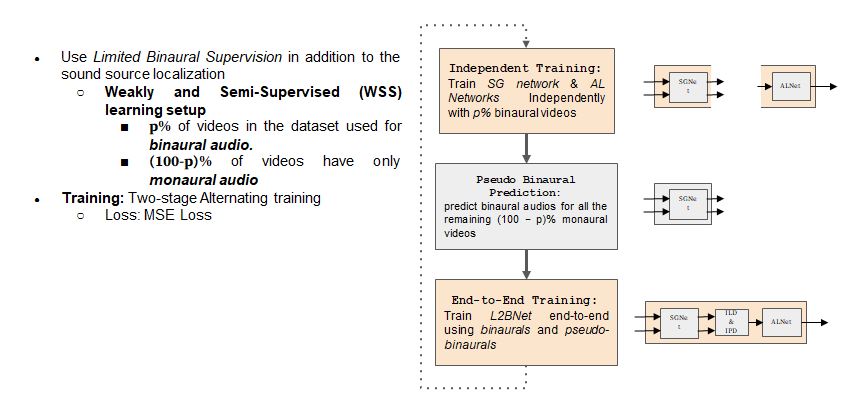
Train L2BNet in an end-to-end learning setup with supervision coming from the localization task alone.
Having established that binaural cues are necessary for sound source localization, We look into the inverse problem of utilizing sound source localization for the task of binaural audio synthesis
For this, we train the L2BNet (both Stereo generation network and audio-localization network) in an end-to-end training setup with supervision coming from only localization task alone.
the audio artefacts such as noise/muffled sound as it can be observed from this clip.
This is because, the problem is highly ill-posed. There are multiple stereo-audio representations with good-localization.
How can we improve the audio quality?
And train it till convergence.
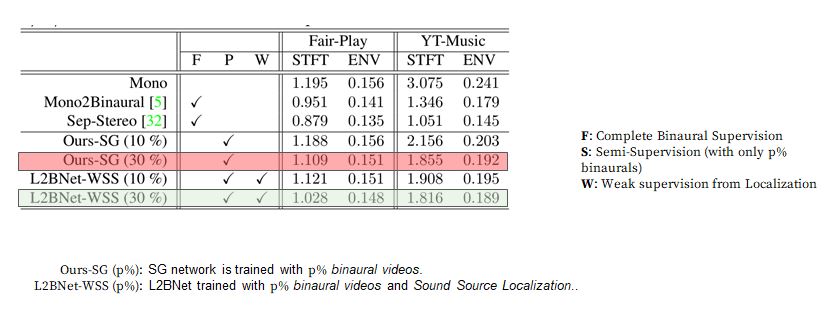
Comparison with other methods
We report STFT/ENV distance on FAIR-Play and YT-Music dataset
Although the performance is inferior to fully-supervised methods, our method generates much better results with weak-supervision from sound-source-localization than with only limited binaural audio.
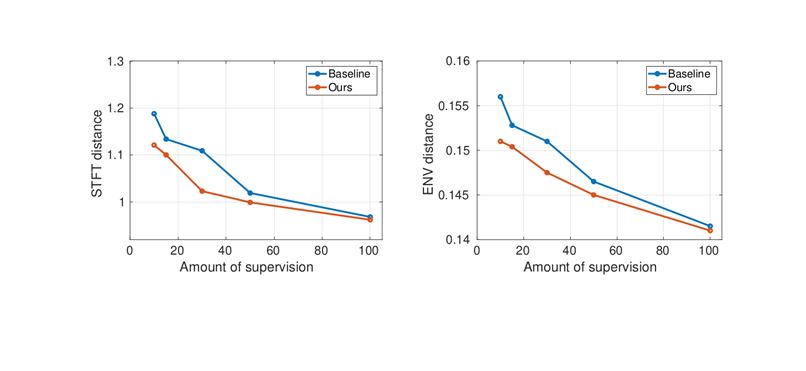
Performance with varying percentages of binaural supervision
We also analyze the performance with varying amount of supervision.
When the explicit binaural supervision is minimal (≤ 30%), our proposed method outperforms, as the localization task contributes significantly in enhancing the binaural cues when ground truth binaurals are limited.
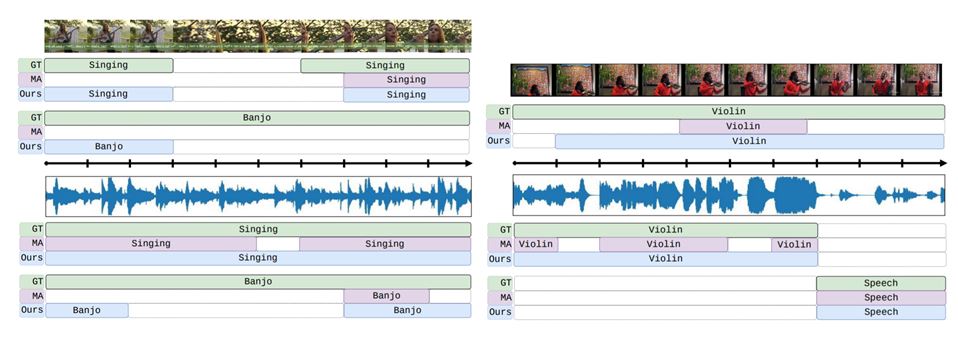
Few Qualitative comparison
Here are a few demo results.
PAPER-3
Weakly-Supervised Audio-Visual Video Parsing with Self-Guided Pseudo-Labeling
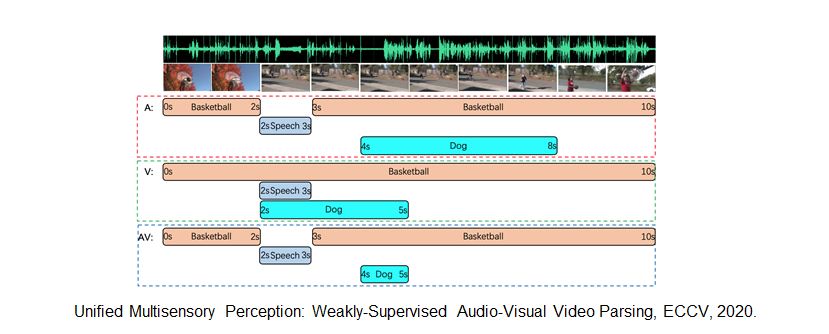
Audio-Visual Video Parsing task
Events in videos can be either
Audible (Audio events)
Visible (Visual events)
Both (Audio-Visual events)
These videos could occur at various temporal locations
Goal: Given a video
Temporally localize events
Classify them into known event categories
Identify whether the event is audible or visible.
Weakly-Supervised Audio-Visual Video Parsing task
To detect and localize events using only video-level event labels.
Training: We only have access to video-level event labels
Evaluation: Predict event labels at segment-level during evaluation.
Challenges:
Absence of segment level labels during training
Multi-modal (audio-visual) processing
Unconstrained videos with varying scene content.
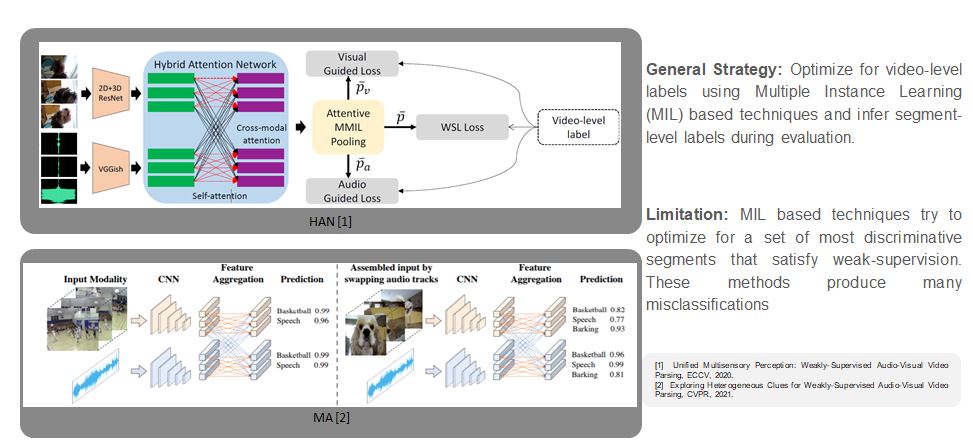
Previous Works
Our Approach: Key Idea
Difference in the training and evaluation setting is a major bottleneck for the weakly-supervised event localization.
Optimizing for the relevant segment-level labels could potentially lead to better localization
But segment-level labels are absent during training
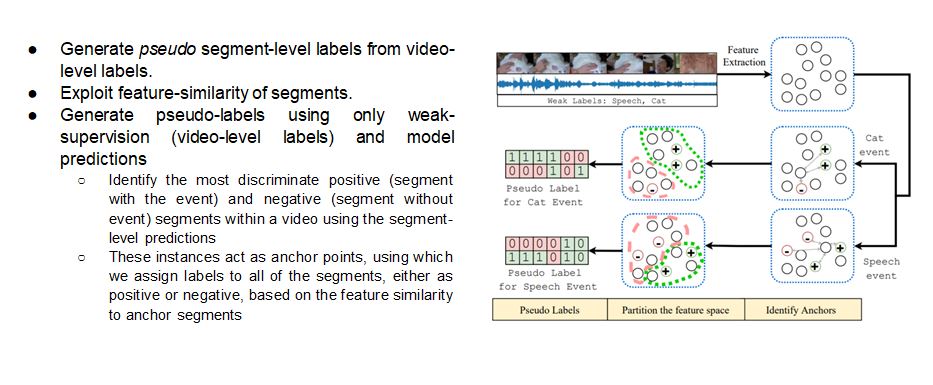
Generate pseudo segment-level labels from video level labels
Self-Guided Pseudo Label Generation
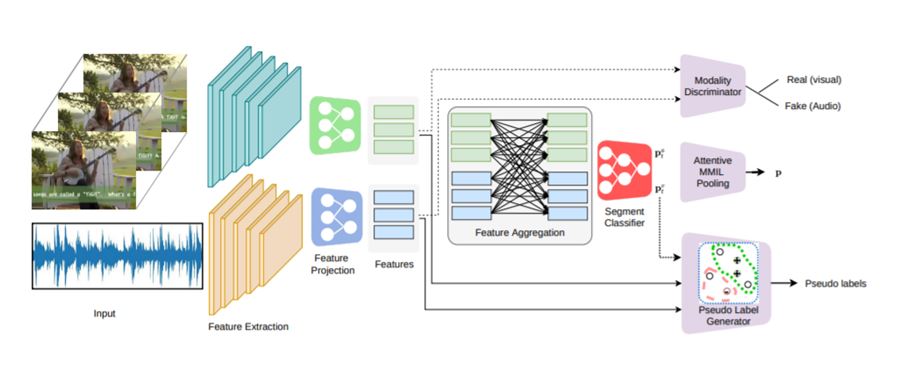
Our Approach: Complete Architecture
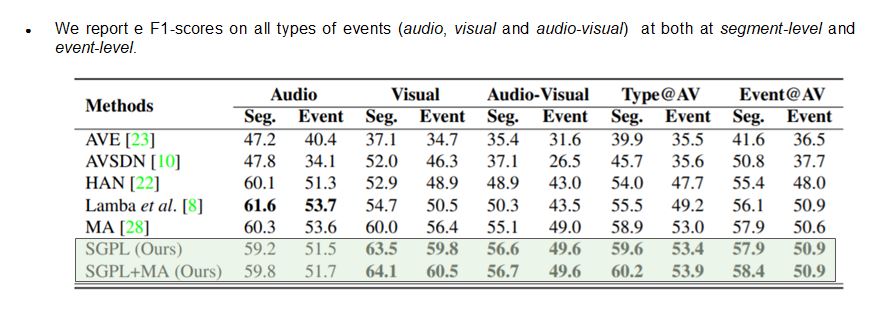
Quantitative Comparison with other methods
PAPER-4
Collaborations
International Collaborations
Prof. Rama Chellappa, Johns Hopkins University, USA
link
The problems defined within the ambit of this proposal are expected to have an overarching reach in terms of societal impact. Research in multimodal learning using text, audio and video with specific focus on leveraging the combination of these modalities to enhance performance will prove to be very relevant for tasks such as emotion detection, in particular assessing depression, and sentiment analysis. With mobile cameras becoming ubiquitous, VR and AR will hold a big sway in how we view multimedia content on our mobile displays.
VR and AR also have important implications in the medical domain, especially in these difficult times of Covid whence these technologies can play a major role in assuaging the mental state of affected people. With regards to the problem of large-scale visual surveillance, our success will have direct implications for any city that wants to call itself ‘smart’. It can make our cities safer and deftly responsive to mishaps in public places including roads, and change the way traffic is controlled and monitored.
Sustenance statement
We believe that it should be possible to sustain ourselves beyond the funding period of IoE. The nature of the problems that we propose to address have direct societal impact which should enable us to get CSR funding from Indian sources, both government and private, without much difficulty.
We will explore joint Indo-US proposals with collaborating faculty to attract new funding. International funding from agencies such as AFRL is certainly a possibility given the cutting-edge nature of these problems.
Funding from government agencies such as DST and Deity can be expected for projects of this nature.
We should also be able to get companies like Samsung and LG to fund our efforts in advancing mobile AR/VR with changing trends. Several Government sectors would also be interested in supporting our research. Also, there is plenty of room to expand the scope of each of these problems and that will help maintain a steady flow of funds.
Technical/ Scientific Progress
New work done in the project
As envisaged in the proposal, we have started working on multi-modal learning with special focus on integrating visual and audio cues. Based on the work done within the ambit of the proposal, we have published a paper in an A-star conference in 2021 which deals with generating stereo from monoaural audio using visual cues in a weakly semi-supervised setting.
In this work, as a proxy-task for weak supervision, we use Sound Source Localization with only audio. We design a two-stage architecture called Localize-to Binauralize Network (L2BNet). The first stage of L2BNet is a Stereo Generation (SG) network employed to generate two-stream audio from monaural audio using visual frame information as guidance. In the second stage, an Audio Localization (AL) network is designed to use the synthesized two-stream audio to localize sound sources in visual frames. The entire network is trained end-to-end so that the AL network provides necessary supervision for the SG network. We experimentally show that our weakly-supervised framework generates two-stream audio containing binaural cues and that our proposed approach generates binaural-quality audio using as little as 10% of explicit supervision data. We have also been investigating the problem of event localization in videos
with self-guided pseudo-labeling where the goal is to temporally localize events that are audible or visible and simultaneously classify them into known event categories. Based on this work, we have submitted 2 papers to an A-star conference in November 2021.
Concurrently, under the umbrella of AR-VR, we worked on the problem of dynamic scene deblurring with unconstrained dual lens cameras. We devised a deep network that addresses view-inconsistency using a coherent fusion module and ensures scene -consistent disparities by introducing a memory-efficient adaptive scale-space approach. This work has been published in a top journal. We are currently working on building a Deep Generative Model that can provide fine-grained and disentangled control over the semantic features of its generated images (with respect to a predefined set of semantic editing tasks) without the need for human supervision. The plan is to submit this work to a top-venue by March 2022.
Infrastructure developments
We are in the stage of issuing Purchase Order for buying a Server with 4 numbers of RTX 3090 GPUs. These are high-end GPUs with 24GB RAM and should significantly augment the compute power in Image Processing and Computer Vision lab.
Output
Mahesh Mohan M. R., G.K. Nithin, A. N. Rajagopalan, “Deep dynamic scene deblurring for unconstrained dual-lens cameras,” IEEE Transaction on Image Processing , vol. 30, pp. 4479-4491, 2021.
Localize to Binauralize: Audio Spatialization From Visual Sound Source Localization, Kranthi Kumar Rachavarapu, Aakansha Jha, Vignesh Sundaresha, A.N. Rajagopalan, Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1930-1939, Oct. 2021. (This is an A-star conference).
Weakly-Supervised Audio-Visual Video Parsing with Self-Guided Pseudo-Labeling, Kranthi Kumar, Kalyan R, A.N. Rajagopalan, submitted to IEEE Conference on Computer Vision and Pattern Recognition.
Temporal Label-Refinement for Weakly-Supervised Audio-Visual Event Localization, Kalyan R, Kranthi Kumar, A.N. Rajagopalan, submitted to IEEE Conference on Computer Vision and Pattern Recognition.
Mobility
Visits planned for PI, co-PIs, international collaborators and students (both inbound and outbound)
Due to the ongoing pandemic, it has been difficult to convince international collaborators to visit us. However, I have submitted a request to the Alexander von Humboldt Foundation to visit Technical University of Munich in the summer of 2022 to interact with Prof. Gerhard Rigoll’s team which works on multi-modal deep learning and AR/VR. The request is under review.
Relationship
University Engagement
As I mentioned earlier, I am have initiated the process for a visit to Technical University of Munich in the summer of 2022 to engage in research in the areas of multi-modal deep learning and AR/VR.